
An event-driven structure is a software program design sample through which decoupled purposes can asynchronously publish and subscribe to occasions through an occasion dealer. By selling unfastened coupling between elements of a system, an event-driven structure results in better agility and may allow elements within the system to scale independently and fail with out impacting different companies. AWS has many companies to construct options with an event-driven structure, comparable to Amazon EventBridge, Amazon Easy Notification Service (Amazon SNS), Amazon Easy Queue Service (Amazon SQS), and AWS Lambda.
Amazon Elastic Kubernetes Service (Amazon EKS) is turning into a well-liked alternative amongst AWS clients to host long-running analytics and AI or machine studying (ML) workloads. By containerizing your knowledge processing duties, you’ll be able to merely deploy them into Amazon EKS as Kubernetes jobs and use Kubernetes to handle underlying computing compute sources. For giant knowledge processing, which requires distributed computing, you need to use Spark on Amazon EKS. Amazon EMR on EKS, a managed Spark framework on Amazon EKS, lets you run Spark jobs with advantages of scalability, portability, extensibility, and velocity. With EMR on EKS, the Spark jobs run utilizing the Amazon EMR runtime for Apache Spark, which will increase the efficiency of your Spark jobs in order that they run quicker and price lower than open-source Apache Spark.
Information processes require a workflow administration to schedule jobs and handle dependencies between jobs, and require monitoring to make sure that the reworked knowledge is at all times correct and updated. One fashionable orchestration instrument for managing workflows is Apache Airflow, which may be put in in Amazon EKS. Alternatively, you need to use the AWS-managed model, Amazon Managed Workflows for Apache Airflow (Amazon MWAA). Another choice is to make use of AWS Step Capabilities, which is a serverless workflow service that integrates with EMR on EKS and EventBridge to construct event-driven workflows.
On this put up, we exhibit methods to construct an event-driven knowledge pipeline utilizing AWS Controllers for Kubernetes (ACK) and EMR on EKS. We use ACK to provision and configure serverless AWS sources, comparable to EventBridge and Step Capabilities. Triggered by an EventBridge rule, Step Capabilities orchestrates jobs operating in EMR on EKS. With ACK, you need to use the Kubernetes API and configuration language to create and configure AWS sources the identical means you create and configure a Kubernetes knowledge processing job. As a result of many of the managed companies are serverless, you’ll be able to construct and handle your whole knowledge pipeline utilizing the Kubernetes API with instruments comparable to kubectl.
Resolution overview
ACK helps you to outline and use AWS service sources instantly from Kubernetes, utilizing the Kubernetes Useful resource Mannequin (KRM). The ACK undertaking incorporates a collection of service controllers, one for every AWS service API. With ACK, builders can keep of their acquainted Kubernetes surroundings and make the most of AWS companies for his or her application-supporting infrastructure. Within the put up Microservices growth utilizing AWS controllers for Kubernetes (ACK) and Amazon EKS blueprints, we present methods to use ACK for microservices growth.
On this put up, we present methods to construct an event-driven knowledge pipeline utilizing ACK controllers for EMR on EKS, Step Capabilities, EventBridge, and Amazon Easy Storage Service (Amazon S3). We provision an EKS cluster with ACK controllers utilizing Terraform modules. We create the information pipeline with the next steps:
- Create the emr-data-team-a namespace and bind it with the digital cluster my-ack-vc in Amazon EMR through the use of the ACK controller.
- Use the ACK controller for Amazon S3 to create an S3 bucket. Add the pattern Spark scripts and pattern knowledge to the S3 bucket.
- Use the ACK controller for Step Capabilities to create a Step Capabilities state machine as an EventBridge rule goal based mostly on Kubernetes sources outlined in YAML manifests.
- Use the ACK controller for EventBridge to create an EventBridge rule for sample matching and goal routing.
The pipeline is triggered when a brand new script is uploaded. An S3 add notification is distributed to EventBridge and, if it matches the desired rule sample, triggers the Step Capabilities state machine. Step Capabilities calls the EMR digital cluster to run the Spark job, and all of the Spark executors and driver are provisioned contained in the emr-data-team-a namespace. The output is saved again to the S3 bucket, and the developer can examine the outcome on the Amazon EMR console.
The next diagram illustrates this structure.

Conditions
Guarantee that you’ve got the next instruments put in regionally:
Deploy the answer infrastructure
As a result of every ACK service controller requires totally different AWS Id and Entry Administration (IAM) roles for managing AWS sources, it’s higher to make use of an automation instrument to put in the required service controllers. For this put up, we use Amazon EKS Blueprints for Terraform and the AWS EKS ACK Addons Terraform module to provision the next elements:
- A brand new VPC with three non-public subnets and three public subnets
- An web gateway for the general public subnets and a NAT Gateway for the non-public subnets
- An EKS cluster management airplane with one managed node group
- Amazon EKS-managed add-ons:
VPC_CNI,CoreDNS, andKube_Proxy - ACK controllers for EMR on EKS, Step Capabilities, EventBridge, and Amazon S3
- IAM execution roles for EMR on EKS, Step Capabilities, and EventBridge
Let’s begin by cloning the GitHub repo to your native desktop. The module eks_ack_addons in addon.tf is for putting in ACK controllers. ACK controllers are put in through the use of helm charts within the Amazon ECR public galley. See the next code:
The next screenshot exhibits an instance of our output. emr_on_eks_role_arn is the ARN of the IAM position created for Amazon EMR operating Spark jobs within the emr-data-team-a namespace in Amazon EKS. stepfunction_role_arn is the ARN of the IAM execution position for the Step Capabilities state machine. eventbridge_role_arn is the ARN of the IAM execution position for the EventBridge rule.

The next command updates kubeconfig in your native machine and lets you work together along with your EKS cluster utilizing kubectl to validate the deployment:
Take a look at your entry to the EKS cluster by itemizing the nodes:
Now we’re able to arrange the event-driven pipeline.
Create an EMR digital cluster
Let’s begin by making a digital cluster in Amazon EMR and hyperlink it with a Kubernetes namespace in EKS. By doing that, the digital cluster will use the linked namespace in Amazon EKS for operating Spark workloads. We use the file emr-virtualcluster.yaml. See the next code:
Let’s apply the manifest through the use of the next kubectl command:
You possibly can navigate to the Digital clusters web page on the Amazon EMR console to see the cluster report.
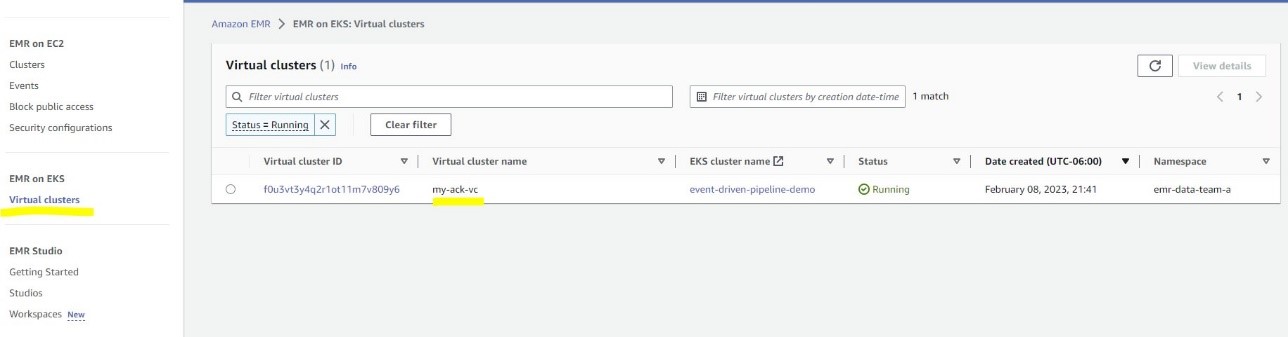
Create an S3 bucket and add knowledge
Subsequent, let’s create a S3 bucket for storing Spark pod templates and pattern knowledge. We use the s3.yaml file. See the next code:
When you don’t see the bucket, you’ll be able to examine the log from the ACK S3 controller pod for particulars. The error is generally precipitated if a bucket with the identical title already exists. You might want to change the bucket title in s3.yaml in addition to in eventbridge.yaml and sfn.yaml. You additionally have to replace upload-inputdata.sh and upload-spark-scripts.sh with the brand new bucket title.
Run the next command to add the enter knowledge and pod templates:
The sparkjob-demo-bucket S3 bucket is created with two folders: enter and scripts.
Create a Step Capabilities state machine
The subsequent step is to create a Step Capabilities state machine that calls the EMR digital cluster to run a Spark job, which is a pattern Python script to course of the New York Metropolis Taxi Data dataset. You might want to outline the Spark script location and pod templates for the Spark driver and executor within the StateMachine object .yaml file. Let’s make the next adjustments (highlighted) in sfn.yaml first:
- Substitute the worth for
roleARNwithstepfunctions_role_arn - Substitute the worth for
ExecutionRoleArnwithemr_on_eks_role_arn - Substitute the worth for
VirtualClusterIdalong with your digital cluster ID - Optionally, substitute
sparkjob-demo-bucketalong with your bucket title
See the next code:
You will get your digital cluster ID from the Amazon EMR console or with the next command:
Then apply the manifest to create the Step Capabilities state machine:
Create an EventBridge rule
The final step is to create an EventBridge rule, which is used as an occasion dealer to obtain occasion notifications from Amazon S3. Each time a brand new file, comparable to a brand new Spark script, is created within the S3 bucket, the EventBridge rule will consider (filter) the occasion and invoke the Step Capabilities state machine if it matches the desired rule sample, triggering the configured Spark job.
Let’s use the next command to get the ARN of the Step Capabilities state machine we created earlier:
Then, replace eventbridge.yaml with the next values:
- Beneath targets, substitute the worth for roleARN with
eventbridge_role_arn
Beneath targets, substitute arn along with your sfn_arn
- Optionally, in eventPattern, substitute
sparkjob-demo-bucketalong with your bucket title
See the next code:
By making use of the EventBridge configuration file, an EventBridge rule is created to observe the folder scripts within the S3 bucket sparkjob-demo-bucket:
For simplicity, the dead-letter queue will not be set and most retry makes an attempt is about to 0. For manufacturing utilization, set them based mostly in your necessities. For extra info, consult with Occasion retry coverage and utilizing dead-letter queues.
Take a look at the information pipeline
To check the information pipeline, we set off it by importing a Spark script to the S3 bucket scripts folder utilizing the next command:
The add occasion triggers the EventBridge rule after which calls the Step Capabilities state machine. You possibly can go to the State machines web page on the Step Capabilities console and select the job run-spark-job-ack to observe its standing.

For the Spark job particulars, on the Amazon EMR console, select Digital clusters within the navigation pane, after which select my-ack-vc. You possibly can assessment all of the job run historical past for this digital cluster. When you select Spark UI in any row, you’re redirected the Spark historical past server for extra Spark driver and executor logs.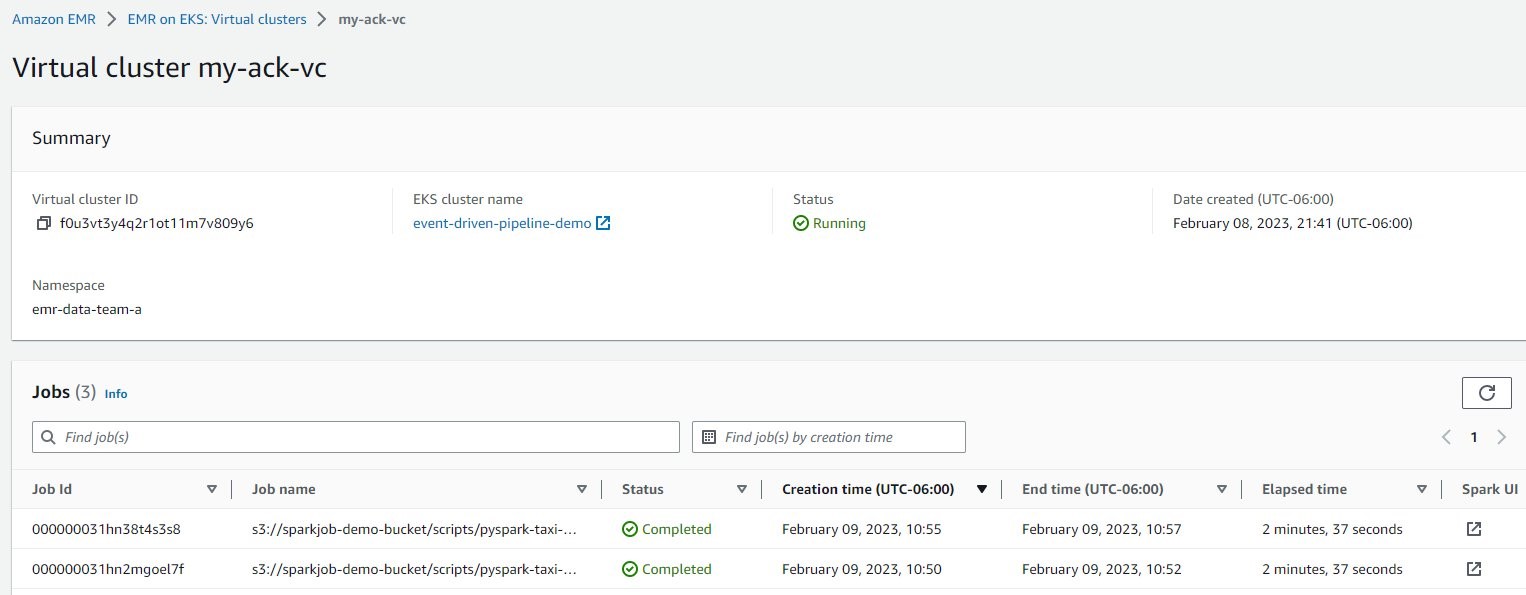
Clear up
To wash up the sources created within the put up, use the next code:
Conclusion
This put up confirmed methods to construct an event-driven knowledge pipeline purely with native Kubernetes API and tooling. The pipeline makes use of EMR on EKS as compute and makes use of serverless AWS sources Amazon S3, EventBridge, and Step Capabilities as storage and orchestration in an event-driven structure. With EventBridge, AWS and customized occasions may be ingested, filtered, reworked, and reliably delivered (routed) to greater than 20 AWS companies and public APIs (webhooks), utilizing human-readable configuration as an alternative of writing undifferentiated code. EventBridge helps you decouple purposes and obtain extra environment friendly organizations utilizing event-driven architectures, and has shortly turn into the occasion bus of alternative for AWS clients for a lot of use instances, comparable to auditing and monitoring, utility integration, and IT automation.
Through the use of ACK controllers to create and configure totally different AWS companies, builders can carry out all knowledge airplane operations with out leaving the Kubernetes platform. Additionally, builders solely want to take care of the EKS cluster as a result of all the opposite elements are serverless.
As a subsequent step, clone the GitHub repository to your native machine and check the information pipeline in your personal AWS account. You possibly can modify the code on this put up and customise it in your personal wants through the use of totally different EventBridge guidelines or including extra steps in Step Capabilities.
In regards to the authors
 Victor Gu is a Containers and Serverless Architect at AWS. He works with AWS clients to design microservices and cloud native options utilizing Amazon EKS/ECS and AWS serverless companies. His specialties are Kubernetes, Spark on Kubernetes, MLOps and DevOps.
Victor Gu is a Containers and Serverless Architect at AWS. He works with AWS clients to design microservices and cloud native options utilizing Amazon EKS/ECS and AWS serverless companies. His specialties are Kubernetes, Spark on Kubernetes, MLOps and DevOps.
 Michael Gasch is a Senior Product Supervisor for AWS EventBridge, driving improvements in event-driven architectures. Previous to AWS, Michael was a Workers Engineer on the VMware Workplace of the CTO, engaged on open-source initiatives, comparable to Kubernetes and Knative, and associated distributed methods analysis.
Michael Gasch is a Senior Product Supervisor for AWS EventBridge, driving improvements in event-driven architectures. Previous to AWS, Michael was a Workers Engineer on the VMware Workplace of the CTO, engaged on open-source initiatives, comparable to Kubernetes and Knative, and associated distributed methods analysis.
 Peter Dalbhanjan is a Options Architect for AWS based mostly in Herndon, VA. Peter has a eager curiosity in evangelizing AWS options and has written a number of weblog posts that concentrate on simplifying advanced use instances. At AWS, Peter helps with designing and architecting number of buyer workloads.
Peter Dalbhanjan is a Options Architect for AWS based mostly in Herndon, VA. Peter has a eager curiosity in evangelizing AWS options and has written a number of weblog posts that concentrate on simplifying advanced use instances. At AWS, Peter helps with designing and architecting number of buyer workloads.